|
For my own regulators, I use the forward drop across an LED to reference a bipolar current source into a fixed resistance. Obviously, fixed
current into a fixed resistance results in a fixed voltage, which is hard referenced and stabilized by the forward drop across the LED. Not incredibly stable, but it is a "hard" enough reference for bias supplies and the like. Very little noise generated compared to a zener diode.
You mentioned using two resistors and a bipolar to make your virtual zener. I assume this is a simple voltage divider, referencing base of an emitter follower--which would be a "soft" device that floats up and down with the main supply variations--am I correct here?
Perhaps you could elaborate for me if you are using a different technique that I am heretofore unaware of…
Dennis
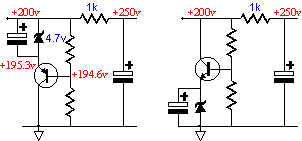
I have found that not all zeners are created equal. The lower voltage and higher wattage types are less noisy than most. (Some zeners come packaged in blue plastic, which signifies tighter tolerances and lower noise.) One test is to attach a series resistor that connects to a much higher voltage power supply and measure the noise at the zener's anode. Interestingly enough, the noise is very stubborn and requires a huge amount of capacitance to shunt it away. A high voltage zener can be made by using a low voltage zener, a large valued (but low voltage) electrolytic capacitor, two resistors and a high voltage transistor. This circuit is a simple shunt regulator. The advantage it holds over a high voltage zener or string of lower voltage zeners is a easily tuned break voltage, much lower noise, much higher wattage, and a slow turn on. The last attribute is vital to many circuits. Because the capacitor is very large, say 10 kµF, it slowly charges, which in turn slowly
|
|